2021年 | プレスリリース・研究成果
深層強化学習による自然なリーチング運動パターン生成 -人間の計測データを用いず7自由度アームの運動シナジーを発現-
【本学研究者情報】
〇大学院工学研究科 ロボティクス専攻 教授 林部充宏
研究室ウェブサイト
【発表のポイント】
- 人間の計測データを使わずに深層強化学習により、自然なリーチング運動パターンを生成できることを示した。
- 運動シナジーの発現度合いが運動学習の習熟度と連動しており、特にエネルギーあたりの運動パフォーマンスと高い相関があることを示した。
- フィードバック制御器と共に用いることで深層学習の速度を3割程度速くできること、またエネルギー効率性とシナジー度合いもさらに高まることを定量的に示した。
- フィードバック制御依存からフィードフォワード制御にシフトする運動学習プロセスを深層強化学習のフレームワークで再現した。
【概要】
これまでの深層強化学習による高自由度関節モデルを用いた運動生成では、タスクは実行できても多くは不自然な運動結果となるため、人間の計測データを用いた模倣学習によって自然な運動パターンを生成するアプローチがとられてきました。
東北大学大学院工学研究科の林部充宏教授とHan Jihui大学院生(研究当時)らの研究グループは、人間の計測データを使わずに深層強化学習によって自然なリーチング運動パターンを生成する手法を提案しました。人間の計測データを一切用いずに、運動習熟レベルが進むほど運動シナジー強度が増大していくプロセスを定量的に再現することに成功しました。真の意味で未知の物理的環境下での運動学習の方法としての解決策やシナジー生成メカニズムを明らかにすることは容易ではなく、どのような計算指針でシナジーが生成されるのかを扱うものがこれまでほとんどありませんでした。本研究では深層強化学習において環境適応性を確保しつつ運動シナジーが発現するプロセスを再現できるかどうかを検証しました。
本研究成果は、Journal誌「IEEE TRANSACTIONS ON MEDICAL ROBOTICS AND BIONIC」に2021年5月20日付けで掲載されました。
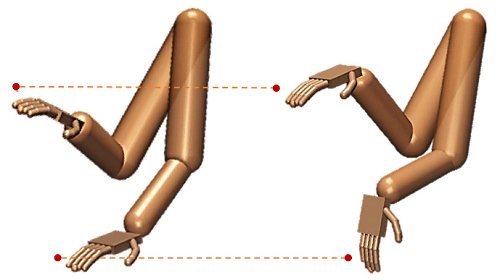
図1 深層強化学習により環境の違いに適応している様子(左側は軽い手、右側は重い手の条件で発現されたリーチング運動の様子)
問い合わせ先
<研究に関して>
東北大学大学院工学研究科 ロボティクス専攻
教授 林部 充宏
TEL: 022-795-6970
E-mail: mitsuhiro.hayashibe.e6*tohoku.ac.jp(*を@に置き換えてください)
<報道に関して >
東北大学工学研究科情報広報室 担当 沼澤 みどり
TEL: 022-795-5898
E-mail: eng-pr*grp.tohoku.ac.jp(*を@に置き換えてください)