2021年 | プレスリリース・研究成果
国際バイオバンク連携によるヒト疾患リスク遺伝子アトラスを構築 日本主導型の国際メタアナリシスでゲノム情報に基づく疾患の精密分類を提案
【本学研究者情報】
〇東北メディカル・メガバンク機構 教授 小柴生造
東北メディカル・メガバンク機構ウェブサイト
【発表のポイント】
- バイオバンク・ジャパン18万人のゲノムデータを基に過去最大220の健康・医療データ(多因子疾患・希少疾患・バイオマーカー※1・服薬データ)に対する網羅的ゲノムワイド関連解析(GWAS)※2を実施。
- 国際バイオバンク連携によりイギリス・フィンランドのバイオバンク※3と計63万人のメタアナリシスを実施し、5,000以上の新規遺伝的リスク関連領域を発見。GWAS結果を公開するデータベースPheWeb.jpを構築し、データシェアリングを推進。
- GWAS要約統計量※4の特異値分解※5と、東北大学東北メディカル・メガバンク機構のメタボローム※6データ等、他のオミクスデータへのプロジェクション解析※7を実施することで、ゲノム情報を基にした従来の疾患分類の精密・層別化方法を提唱。
【概要】
全世界のヒトゲノムデータの蓄積に伴ってこの20年ほどで実施されてきたGWASにより、ヒトの遺伝的変異と将来の疾患発症リスクとの関係が網羅的に判明しつつあります。得られたゲノムデータを基に、長い医学の歴史から構築されてきた多彩なヒトの病気の分類について、客観的に振り返ってみたらどうなるでしょうか? この疑問に適切に答えるためには、従来のゲノム研究の課題である、①:ゲノム研究データが欧米人集団に偏重して構築されていること、②:研究対象となる疾患の網羅性が低かったこと、③:得られた大量のGWAS結果を医学的・生物学的に解釈する方法論が確立されていないこと、の3点を解決する必要がありました。
大阪大学大学院医学系研究科の坂上沙央里助教(研究当時、現ハーバード大学医学部博士研究員)、金井仁弘特別研究学生(ハーバード大学医学部 博士課程)、岡田随象教授(遺伝統計学 / 理化学研究所生命医科学研究センター自己免疫疾患研究チーム 客員主管研究員)、東京大学大学院新領域創成科学研究科 松田浩一教授らの研究グループは、国際バイオバンク連携を通じて、バイオバンク・ジャパン(日本)・UKバイオバンク(英国)・FinnGen(フィンランド)の計63万人のゲノムデータと健康・医療データの網羅的な解析を実施しました。多因子疾患・希少疾患・バイオマーカー・服薬データまでを網羅する過去最大220のヒト形質のゲノムワイド関連解析(GWAS)により、ヒト疾患に関わる5,000以上の新規遺伝的リスク関連領域が発見されました。研究グループは、各疾患の遺伝的リスク構造が遺伝的集団※8を超え共有されていることを示すとともに、得られたゲノム解析アトラスを医療に役立てる方法として、GWAS要約統計量を特異値分解し遺伝学を基にした疾患群の再分類を試みました(図1)。東北大学東北メディカル・メガバンク機構が構築したメタボロームデータ等、他のオミクスデータへのプロジェクション解析、エピゲノム情報やパスウェイ等との多分野融合的な解析を実施し、GWAS要約統計量行列を数理学的に分解する工程を経て、より複雑な疾患(例: 心筋梗塞)のリスクを単純な形質の足し合わせとして解釈すること(例: コレステロールと血圧)や、ゲノム変異を基にした疾患の精密分類・層別化方法の提唱(例: I型アレルギーとIV型アレルギー疾患の分類)に成功しました。さらに、本研究結果を広く利用促進することを目的にデータシェアリングサイトPheWeb.jp(https://pheweb.jp/ ![]() )を構築しデータを無償・非制限公開し、Polygenic risk score(PRS)※9をはじめとするゲノム個別化医療の社会実装基盤として広く利用されることが期待されます。
)を構築しデータを無償・非制限公開し、Polygenic risk score(PRS)※9をはじめとするゲノム個別化医療の社会実装基盤として広く利用されることが期待されます。
本研究成果は、米国科学誌「Nature Genetics」に、10月1日(金)午前0時(日本時間)に公開されました。
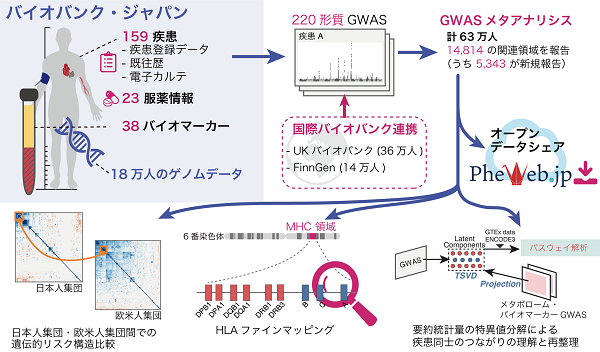
図1. 日本主導の国際バイオバンク連携により、220のヒト形質のGWASと横断的メタアナリシスを実施して結果を公開するとともに、医療に役立てる方法論を提唱
【用語解説】
※1 バイオマーカー
ヒトの疾患病態や生物的特徴の説明に役立つ、測定指標のこと。体重、血圧などの身体測定値や、コレステロールや尿酸などの血液検査値が含まれる。
※2 ゲノムワイド関連解析研究(GWAS:Genome Wide Association Study)
ヒトゲノム配列上に存在する数百〜数千万カ所の遺伝的変異(とくに一塩基多型・SNP)とヒトの疾患発症リスクや個人差(形質)との関連を網羅的に検討する、遺伝統計解析手法。
※3 バイオバンク
疾患疫学や病態研究などを目的に、多数のヒトのDNA、血清、尿、組織などの検体を収集、蓄積、管理する施設のこと。近年では国家レベルで数十万人を対象とするバイオバンクが構築され、個人の検体とともに電子カルテ上の臨床情報やその後の予後などの追跡情報も蓄積される例が多い。
※4 要約統計量 (summary statistics)
GWASの関連解析結果の主となる統計量をまとめた表のことで、一般的には全ゲノムに渡る遺伝的変異の名称や位置情報と、線形回帰やロジスティック回帰の結果のP値(=統計学的な有意性)・beta値(=リスクの方向性・大きさ)・標準誤差、解析サンプル数などの情報がまとめられたもののことを指す。元のゲノムデータや形質データと異なりプライバシーの問題がないため、GWAS結果を他機関に共有する際の基本的な情報として利用される。
※5 特異値分解 (SVD: singular value decomposition)
線形代数において、正方行列に限らない任意の行列を複数の行列の積として分解する手法の一つ。 任意の実行列Aに対して得られる特異値分解A=UΣVでは、ΣはAの特異値を対角項にもつ矩形行列、UとVは直交行列となる。本論文ではtruncated SVDという応用手法により、指定した階数(< rank(A))までの分解を実施し、複雑な遺伝子変異―疾患間の遺伝的相関関係を、得られた成分の組み合わせとして表現した。
※6 メタボローム (metabolome)
生体内の低分子化合物質(代謝物: metabolite)の総体(-ome)のこと。質量分析法等により網羅的に代謝物を測定する技術が近年発達し、数千種類におよぶ代謝物の量を測定することができる。
※7 プロジェクション解析
疾患形質に対する特異値分解によって得られた遺伝的変異と各要素の関係の大きさと符号を表す重み情報を用いて、新たなGWAS要約統計量を特異値分解の要素に投影し、それぞれの要素に対してどのくらいの貢献度があるか定量する解析のこと。
※8 遺伝的集団 (population)
英語におけるpopulation、すなわちある遺伝学的背景を共有した任意の集団(データから科学的に定義された任意の集団)のことで、本研究においては日本語訳の一例として「遺伝的集団」を使用している。より狭義のancestry(遺伝学的背景を共有した集団かつ、歴史的にも遺伝的祖先を共有していると考えられる集団、日本語訳の例: 遺伝的祖先)や、社会的に構築されたニュアンスを含むrace(日本語訳の例: 人種)やethnicity(日本語訳の例: 民族)とは異なる意味で使用している。
※9 Polygenic risk score(PRS)
大規模なゲノムワイド関連解析研究(GWAS)により疾患や形質との関連が示唆された数十〜数千の遺伝的変異の重み付きの和を個人ごとに計算したスコア。このスコアは実際の疾患発症リスクと相関することが示されており、集団内でスコアの分布を調べることで、特にその疾患のリスクが高い個人を特定することができる。
問い合わせ先
東北大学東北メディカル・メガバンク機構 広報戦略室
室長 長神 風二(ながみ ふうじ)
電話番号:022-717-7908
Eメール:pr*megabank.tohoku.ac.jp(*を@に置き換えてください)
![]()
![]()
東北大学は持続可能な開発目標(SDGs)を支援しています